

Drupal Ontwikkeling eenvoudiger met de Qt Assistant - Deel 3b
Weet je nog hoe we de vorige keer Doxygen commentaar in Drupal dusdanig verwerkte, zodat het ook in de uitvoer van Doxygen er goed uit zou zien? Tijd voor een nieuw deel in de serie, en we gaan nog even door met reparaties. Moet je de boel nog goed opzetten, omdat je de eerdere delen misschien gemist hebt? Lees dan eerst delen 1, 2 en vooral 3a voordat je verder gaat. Deze keer: het werkend krijgen van speciale HTML documentatie zoals de Forms API. Beginnen maar!
Het probleem
In de Drupal documentatie worden alle links, inclusief die naar andere pagina's, gemaakt met behulp van het @link commando. We hebben eerder al de externe en Drupal-specifieke links gerepareerd. Onze Doxygen documentatie bevat echter nog steeds sommige onderwerpen niet omdat Doxygen HTML files niet zomaar oppikt of toevoegt. Vanwege de manier waarop Doxygen alles verwerkt, blijven de gedefinieerde links wijzen naar iets dat niet bestaat. De links werken dus niet, en we hebben de documentatie niet bij de rest zitten.
We kunnen natuurlijk gewoon de links aanpassen en naar de externe pagina's op api.drupal.org laten wijzen. Maar zou het niet beter zijn als we alle documentatie op dezelfde plek hebben? Daar gaan we nu voor zorgen!
Meer preprocessen
Herinner je dat we in onze preprocessor wat ruimte hadden overgelaten voor HTML verwerking? We gaan nu een HtmlPreprocessor toevoegen. Later zorgen we ervoor dat Doxygen de HTML bestanden ook meeneemt. Met onze speciale preprocessor zorgen we dat Doxygen de HTML pagina's maakt en toevoegt. Vervolgens kunnen we daar naar linken ook al passen we de links niet aan.
Eerst wat structuur. Open het preprocess-drupal-doxygen.php bestand in je teksteditor of IDE. Onder de CodePreprocessor klasse, voeg je het volgende skelet toe:
class HtmlPreprocessor extends Preprocessor {
private $_basename = ''; /**< The basename of the filename */
public function __construct ($filename) {
Preprocessor::__construct($filename);
$this->_basename = basename($filename);
}protected function doProcess($contents) {
// We will go and fill this in soon...}}
De constructor hebben we al gemaakt, die slaat de basisnaam van het bestand dat we verwerken op (dat is de bestandsnaam zonder pad of directory-informatie). Dat hebben we verderop nodig. De doProcess() functie is er ook al bij, maar heeft nog wat inhoud nodig.
Vergeet niet dat de $contents variabele het hele HTML document opslaat. Dit is inclusief headers, rommel op het eind en nog veel meer. Maar voor toekomstige handigheid, of zelfs voor je eigen projecten, wil je misschien een simpele HTML pagina met alleen de inhoud maken. Dat bestand zelf is dan misschien geen correcte HTML, maar dat komt wel goed als we het in Doxygen zetten. Wat de invoer ook is, we gaan het zo goed mogelijk vewerken.
Vissen naar de titel
Het eerste deel van de doProcess functie haalt de titel uit het document. Bij voorkeur staat deze in een <title> tag. Maar als we geen header hebben en deze tag niet bestaat, willen we misschien zoeken in tags als <h1> tot en met <h6>. Voor elk van deze tags kijken we of die in het document voorkomt en niet leeg is. We pakken de inhoud van de tag en zorgen dat alles op één regel staat. Mocht het document dan de regel midden in de titel afbreken, dan schopt dat onze documentatie niet in de war.
Als er geen tags gevonden worden, vallen we terug op de oorspronkelijke bestandsnaam. Hiermee krijgen we dus de volgende code, waarvan de reguliere expressie is geïnspireerd op code uit de Drupal API module:
// Find title in the first listed tag that's in the file$title = NULL;
$titleTags = array('title', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6');
foreach($titleTags as $tag) {
$titleMatch = array();
if (preg_match('@<' . $tag . '(\s.*?)?>\s*(\w.*?)\s*</' . $tag . '\s*?>@is', $contents, $titleMatch)) {
$title = str_replace("\n", " ", $titleMatch[2]); // Make sure it's all on one line
break;
}}if (!isset($title)) {
$title = $this->_basename;
}
En de rest?
Nu de daadwerkelijke inhoud. We hebben twee gevallen, zoals eerder beschreven: geval één is dat het bestand een volledige HTML pagina is (inclusief header enzovoorts, en de erg belangrijke <body> tag), of we hebben een wat rommeliger document met alleen de inhoud zelf (zonder <body> tag).
Wat doen we dan? Zoals hierboven ook gedaan is, gaan we de inhoud van de <body> tag proberen te pakken te krijgen. Vinden we niks, dan pakken we gewoon het hele bestand:
// Get <body> of HTML, if present (otherwise use whole document)$bodyMatch = array();
if (preg_match('!<body(\s.*?)?>(.*)</body(\s.*?)?>!is', $contents, $bodyMatch)) {
$contents = $bodyMatch[2];
}$contents = str_replace("\n", "\n * ", $contents);
$contents = preg_replace('!([@\\\\])endhtmlonly!', '\\1<span>endhtmlonly</span>', $contents);
De op een na laatste regel springt elke regel in met " * ". Doxygen haalt dit weer weg uit z'n uitvoer. Maar waarom doen we dat dan? Stel dat het HTML document ergens een regel heeft die begint met " * ", dan willen we dat behouden in de uitvoer. Door deze inspringing toe te voegen, verwijdert Doxygen alleen het extra toegevoegde deel en niets anders.
Een ander probleem is dat het document het Doxygen commando @endhtmlonly kan bevatten. Zoals je later zult zien, kan dit problemen veroorzaken omdat het ons @htmlonly blok, waarmee we hieronder de HTML code letterlijk zullen invoegen, zal afbreken. Let op dat in dit blok alleen het @endhtmlonly door Doxygen herkent wordt. Het escapen van het commando heeft geen zin, dus we gaan het een beetje "slopen" waar het ook voorkomt. Dit doen we door het endhtmlonly deel in een (verder nutteloze) <span> tag te zetten. Je ziet geen verschil, maar Doxygen ziet @<span>endhtmlonly</span> en blijft doorgaan met het uitspugen van letterlijke HTML code. Succes gegarandeerd!
Het laatste probleem dat we hebben is dat er nog referenties naar andere documenten te vinden is. De Forms API Quickstart en Forms API Reference wijzen bijvoorbeeld naar elkaar, door middel van absolute links naar api.drupal.org. Het werkt, maar we hebben alle documentatie al in Doxygen, dus waarom kunnen we niet daar naartoe linken?
We gaan dus wat links vervangen. Voeg de volgende functie toe aan de HtmlPreprocessor:
private function replaceLinks($contents, $links) {
foreach($links as $original => $new) {
$re = '/(<a\s+[^>]*)href=(["\'])' . str_replace('/', '\/', $original) . '(\/\S*)?\\2/si';
$contents = preg_replace($re, '\\1href=\\2' . $new . '\\2', $contents);
}return $contents;
}
Deze functie zoekt links op die we in de $links array meegeven (als array sleutels), en vervangt deze met de bijbehorende waarde uit de array. Ook langere URLs worden meegenomen, als de URL verder gaat met een slash en dan de rest. Gevolg is dat een link naar http://api.drupal.org/api/file/developer/topics/forms_api_reference.html/6 verandert in gewoon forms_api_reference.html als we de functie als volgt aanroepen (voeg dit toe aan de doProcess() functie):
$contents = $this->replaceLinks($contents, array(
'http://api.drupal.org/api/file/developer/topics/forms_api.html' => 'forms_api.html',
'http://api.drupal.org/api/file/developer/topics/forms_api_reference.html' => 'forms_api_reference.html',
'http://api.drupal.org/api/file/developer/topics/javascript_startup_guide.html' => 'javascript_startup_guide.html',
));
Nu de belangrijkste stap: een Doxygen commentaarblok maken en de HTML code invoegen. We geven Doxygen wat documentatie over het bestand zelf, en maken daarnaast een Doxygen pagina met wat HTML inhoud. Dit gebeurt met het volgende blok:
$contents = "/**\n"
// Clone page's documentation in File listing. " * @file\n"
. " * @brief @link {$this->_basename} {$title} @endlink\n"
. " * \n"
. " * This file contains a special documentation topic: @link {$this->_basename} {$title} @endlink.\n"
. " */\n"
// Create custom page. "/**\n"
. " * @page {$this->_basename} {$title}\n"
. " * \n"
. " * @htmlonly\n"
. " * " . $contents . "\n"
. " * @endhtmlonly\n"
. " */\n";
return $contents;
Het enige probleem dat hier over blijft is dat de documentatie van het bestand, als je via de bestandenlijst van Doxygen gaat, niet de documentatie zelf bevat. In plaats daarvan is er alleen een verwijzing naar de eigen pagina die gemaakt is, waar wel alles staat. Als je dat prettiger vindt, kun je de drie regels vanaf @htmlonly tot @endhtmlonly kopieren naar de bestandsdocumentatie. Je moet echter de andere pagina laten staan, anders zullen de (ongewijzigde) links naar de pagina niet werken.
Je kunt nu naar de documentatie waar je maar wilt met behulp van het Doxygen commando @link (bijv. "@link bestand.html Mijn Link Tekst @endlink").
Er is nog een laatste ding dat onze preprocessor moet doen: de HtmlPreprocessor maken en gebruiken. Als je het script van de vorige keer hebt gebruikt, zoek dan de regel (vrij ver onderaan) op, waar staat // HTML Processing is for later.... Gevonden? Vervang deze regel met de volgende:
$processor = new HtmlPreprocessor($filename);
Dat is alles voor de preprocessor. Als je ergens de weg kwijt bent geraakt, kun je het hele script hieronder downloaden. Alle code is overigens GPL v2 code, dus voel je vrij om het aan te passen, te hergebruiken en verder te verspreiden.
Maar Doxygen leest nog steeds geen HTML bestanden!
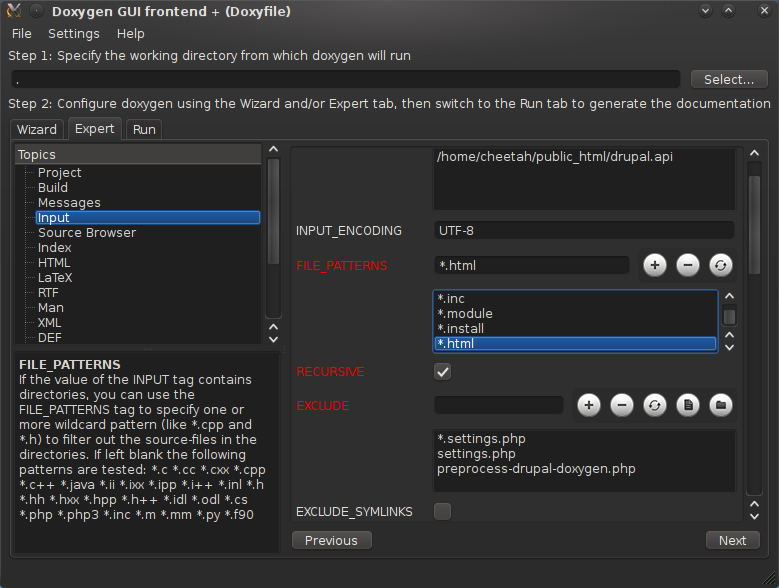
Nu de preprocessor helemaal klaar is, kunnen we Doxygen de HTML bestanden laten gebruiken. Dit is relatief eenvoudig: eerder lieten we Doxygen alleen maar .php, .inc, .module en .install bestanden voor Drupal verwerken. Voeg gewoon .html (en eventueel andere extensies die je gebruikt) toe aan de FILE_PATTERNS lijst (Input onderdeel) in de Doxywizard. Voer Doxygen uit, en de documentatie wordt netjes toegevoegd. Voor de Drupal documentatie kun je dit gelijk zien op de hoofdpagina met onderwerpen. Als alles klopt, werkt alles zoals verwacht.
Samenvatting
In deel 1 hebben we het systeem klaargemaakt, in deel 2 hebben we de Drupal documentatie in de Qt Assistant gezet. Nu hebben we fouten in de documentatie opgelost met wat eigen code uit deel 3a en dit deel. Vorige keer hebben we wat verschillen tussen de Drupal API module en Doxygen wat betreft het verwerken van commando's gecorrigeerd, zodat de Doxygen uitvoer overeenkomt met die van de module. Deze keer hebben we de code uitgebreid om geavanceerde onderwerpen uit HTML pagina's toe te voegen.
Er is nog een laatste probleem. Alle documentatie, van Drupal core en alle modules, is op een grote hoop gegooit. Vaak is het echter wel prettig om de documentatie van een specifieke module te bekijken. Qt Assistant ondersteunt dit door ons een selectie van documentatiecollecties te tonen (en dat kan de hele bundel zijn, zoals nu). Hoe? Dat lees je binnenkort.
Andere delen in deze serie:
| Bijlage | Grootte |
|---|---|
| Doxyfile. | 62.98 KB |
| preprocess-drupal-doxygen.phps | 12.45 KB |
Recente reacties
14 jaar 9 weken geleden
14 jaar 9 weken geleden
14 jaar 10 weken geleden
14 jaar 25 weken geleden
14 jaar 25 weken geleden
14 jaar 25 weken geleden
14 jaar 30 weken geleden
14 jaar 30 weken geleden
14 jaar 30 weken geleden
14 jaar 30 weken geleden